If you talk to someone about Google Analytics it’s only a matter of minutes before they talk about the BigQuery export. What was previously a paid feature in Universal Analytics, with annual licenses starting at $100K, became a free feature in GA4. There are a huge number of benefits to having your raw data in BigQuery (but is the subject of many other blog posts that you can find on Google), but storing data in BigQuery comes with an additional complication: how do I control who can access my data?
This becomes even more important when you’re working with global brands, ingesting data from other data sources such as CRM, eCommerce platforms, ERP and Email Marketing, where you’ve got business sensitive data and Personally Identifiable Information (PII) and as a responsible data steward you want to restrict access to specific data to those who need to know.
Managing access is one of the most common day-to-day Google Cloud Platform (GCP) admin tasks that we get asked to do by clients, and all too often we see cases where there is legacy Identity and Access Management (IAM) debt means that everyone has complete access to everything, or even worse, everyone is an owner!
If you just want to see our best practice, skip to Our Advice

Resource Hierarchy
To understand how to do BigQuery IAM, you first have to understand what Google calls the “Resource Hierarchy”. This is a way to model all the resources within your cloud platform where every resource, whether that’s a BigQuery Table, Compute Engine instance, Cloud Run Service, Folder or Project, is a child of another resource.
Organisations
If you’ve got your Google Cloud set up correctly, your top resource will be your Organisation. This is a special resource, which is connected to your Google Workspace or Cloud Identity accounts (these are probably managed by your IT teams). An Organisation means you have an extra level of governance over your projects, visibility over your entire organisation, and it reduces the risk of projects disappearing when the Owner leaves the company.
If you see “No Organisation” in your project selector in GCP then get in touch and we can help you get this set up.

Inheritance
One key part of the resource hierarchy is inheritance. Every resource has a parent and inherits properties from its parent. These include things like Organisation policies, which allow you apply global restrictions across all your projects and can dictate things like which regions users can create resources in – if you’re an EU company you might want to turn this on to prevent someone storing your data in a US data centre – and which domains can be added to your organisation to prevent a rogue account being added, and of course, Identity Policies.
How does this inheritance work? A role can be assigned to any resource. You’ve probably seen this before, when you open the IAM & Admin page and assign a role. This is assigning a role a the `Project Level`. What this actually means is that the role is assigned to the project and every resource that sits underneath it in the resource hierarchy.

So if you assign the role “BigQuery Data Editor” (we’ll look at the roles in a minute) at the project level, that “role” is also applied to every BigQuery dataset, table, job, transfer etc. in the project. You can see your inherited permissions in action in the BigQuery dataset sharing console.


If you want to inspect your GCP Resource Hierarchy and see the permissions across all your resources, you can do it at https://www.accessium.io/audit/gcp/login
GCP Roles
So what is a role? A role is a collection of permissions. If you take the role BigQuery Job User, it contains these permissions:
- bigquery.config.get
- bigquery.jobs.create
- dataform.locations.get
- datform.locations.list
- dataform.repositories.create
- dataform.repositories.list
- resourcemanager.projects.get
- resourcemanager.projects.list
Whenever you interact with any GCP Resource, Google checks your permissions and whether you have the required permission for the request.
Let’s look at the BigQuery Job User role. If you tried to create a dataform repository, you’d be able to do that because you have the dataform.repositories.create permission, but if you tried to delete a repository, you wouldn’t be able to because you don’t have the dataform.repositories.delete permission.
You don’t have to know all of these, you can see all the pre-defined roles, which permissions they contain and what the permissions allow on this page https://cloud.google.com/bigquery/docs/access-control.
Assigning Permissions
The final piece of the puzzle to understand is which level of the resource hierarchy you need to assign permissions at.
Some permissions have to be assigned at the project level (in the IAM panel). That’s because they interact with a project level resource. Others can be assigned at a lower level, on the dataset or the table. You edit these in the resource. Open the Dataset and Click the Sharing button in the top right, then click Permissions.
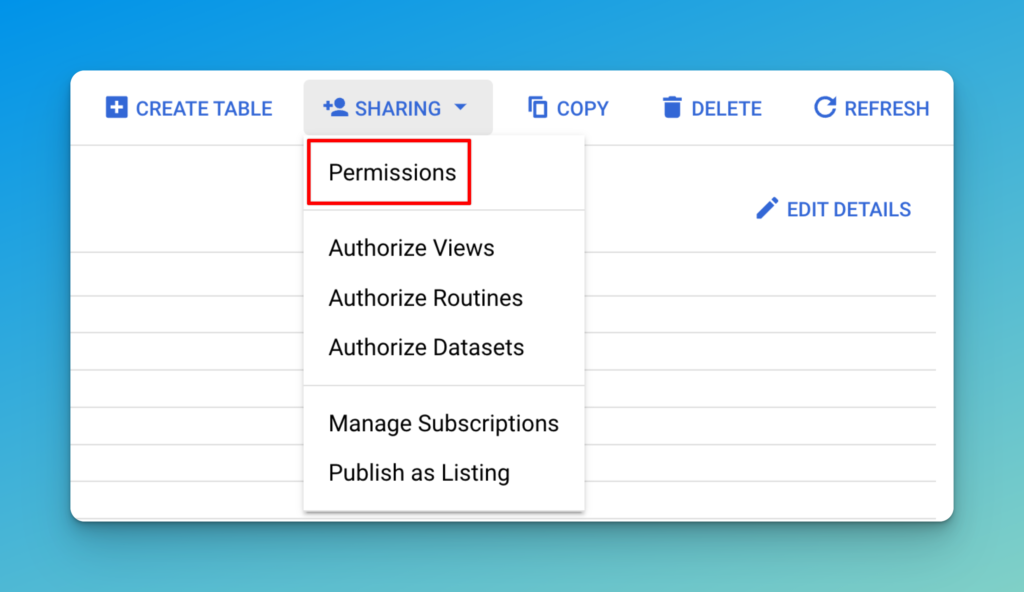
In the case of BigQuery, the most common problem we see is people not being able to run a query. Someone has tried to be good and only give access to a dataset, but they’ve not given permissions to run a query, or they’ve given the right role at the wrong level. This is because when you run a Query, you create a Query Job.

Project Level Roles
A Job is a project level resource; it uses your project quota and billing. This means that you need to have the permission biquery.jobs.create at the project level. There are four different types of job:
- Query
- Load
- Copy
- Export.
There are three pre-defined roles that include this permission BigQuery Job User, BigQuery User and BigQuery Admin but these have to be applied at the project level or above.
You can’t assign Job User at a lower level, but if you assign BigQuery User or BigQuery Admin at the Dataset level, that doesn’t allow jobs to be created. It’s important to note that the other roles includes many more permissions than the BigQuery Job User role, so when you’re applying principle of least privilege we recommend the BigQuery Job User role.

Project/Dataset/Table Level Roles
Roles that apply to accessing and editing data can be applied at the project, dataset or table level.
You can assign the BigQuery Data Viewer role at the project level, and that will enable the user to see every table in the project.
If you then assign the BigQuery Data Editor role to a dataset, the user will still be able to see every dataset and table in the project, but they can also edit that specific dataset and every table within it.
These roles DO NOT give a user permission to run a job. If you don’t have the bigquery.jobs.create permission in the project you’re using (the one in the project selector) you won’t be able to run a query, even if you have permissions to view the table.
Key BigQuery Roles
There are a number of roles to pick from in BigQuery, and what each one allows depends on which level you assign them. For the full list and details, use the Google Documentation, but the five key roles you’re most likely to use are summarised here:
Job User
A project level role required to run Jobs.
Data Viewer
Read-Only access. You can’t change the table structure, metadata, dataset settings or anything else.
Data Editor
Data Viewer + Update data and metadata, create, update and delete tables and create datasets.
Data Owner
Data Editor + Delete Datasets and manage Table and Dataset IAM
Admin
All the permissions to do everything. This is also includes BigQuery Transfers, which are required for Scheduled Queries. If you’ve got users who need to set up Scheduled Queries consider a custom role.
How a query works
There are two parts to a query:
- The data access
- The query execution
These can be in two different projects. This is a key concept, so remember it! You’ve almost certainly used this feature, querying any of the datasets in the bigquery-public-data project. You can access the data, but you can only run a query in your own projects.
Which project the query is executed in is determined by the project in your project selector (Or your code configuration if you’re querying in another way.) This project is the one that pays the bills for the query and the one that logs. This doesn’t have to be the same project that your data are stored in. You just need permission to read the data.
Side Bar: Cross Project querying means you can access data from multiple sources in a single query. This means there is no reason for you to own your customer’s data. If you’re an agency or supplier setting up for a customer and you can’t get a project immediately in their organisation or if they haven’t set up GCP yet and you’re desperate to set up the GA4 Export then create a brand new project for them and transfer it to them as soon as possible. Never store their data in a generic project.
Our Advice
So what does all this mean, and how do you do it?
Keep It Simple
- Assign the
BigQuery Job User roleat the project level. This will allow users to query data within your project, use your project quota and attached billing account. Without this they can’t run queries in the project. That doesn’t mean they can’t run any queries, but they’d have to be run from a different project. - Identify the access requirements for the user (or group of users) and assign exactly that. If you’re working with an advertising agency for one country in your global brand, they don’t need access to every analytics dataset for your brand, so give them access to just the dataset they need. They also don’t need to edit the data, so give them the Data Viewer role.
- Separate your datasets. If a team needs to store results for reporting, give them their own dataset to keep tables in. Name the datasets so you know exactly what’s in it and who uses it. Give them the Data Editor role on that dataset. (Top Tip: Create two datasets, one production, one development and set the development table expiration to 7 days, it saves you paying storage costs for an old, dev table that’s not being used)
IAM can be seem complicated. If you always think about the Principle of Least Privilege (PoLP) then you won’t go wrong. If you can’t remember what something does or what level it’s applied at, always go lower and less. If the end user can’t do what they want to then they’ll tell you pretty quickly and you can either increase the permissions or apply them at a higher level. It’s better to do that than start with excess permissions and revoke them later.
Slightly more advanced bits
Getting the basics right is the most important thing. Once you’ve got them sorted there is even more that you can do with BigQuery to secure your data and optimise your setup.
Custom roles
These enable you to choose exactly the permissions you want to give a user. The Job User role also allows a user to create a dataform repository, but doesn’t allow scheduled queries. That might be fine, but you may want something more granular where you can pick exactly what you want your users to be able to do. The permissions below allow the user to run queries and create and manage scheduled queries, but no access to dataform.
- bigquery.transfers.get
- bigquery.transfers.update
- bigquery.jobs.create
- bigquery.config.get
- resourcemanager.projects.get
This would replace the Job User role at the project level.

Column Level permissions
Your marketing and analytics agencies don’t need to see your customers’ names, addresses and emails. Fact. If they say they need it then be very, very wary! They probably need other fields in those tables such as order items, shipping costs and order total, but not the PII.

That’s where Column Level Access comes in. Using GCP Data Catalog you can tag columns based on the type of information they contain (PII: Email, PII: Address etc.) and then only give access to those columns to those who need them.

This doesn’t just apply to agencies, this applies equally to internal teams too. Users are the biggest risk of a data breach to your organisation, so if they don’t need access to PII data then restricting access only improves your security posture. An alternative to this is to create an Authorised View in a different dataset that excludes the PII/Sensitive columns, however that increases your management overhead, maintaining multiple views with different columns.
Organise your billing
If you’ve got lots of teams using BigQuery, you might want to know who’s spending what so it can be billed back to the correct cost centre.
You could do this by looking at all the queries, mapping users to cost centres and calculating it manually, or you can use “Query Projects”. To do this, you create different projects to your Storage Projects. Users are given access permissions to your storage projects (Data Owner/Editor/Viewer) and then given Job permissions on their relevant Query project. Billing will be assigned to the Query project and you can see exactly who spends what.
Mass Account Management
If you’re working with a big company, this can get complicated, especially if you’re managing multiple users and multiple projects.
If that’s the case you can use an Infrastructure as Code tool such as Terraform to automate the management and bulk update access, use an access management platform to create and manage profiles that contain multiple permissions, or use Google Groups – assign the roles to the group and then add users to the groups.
The setup process might be a bit longer to get started, but when you have to add another new user to 20 datasets, or change the roles of 8 users on 10 datasets (I’ve had to do both recently!) you’ll be grateful you put in the initial effort!
Summing up
- Queries are Jobs, to run a query you need the permission to create a job. This is Project Level.
- You need access to the data you’re querying, this can be given at any level.
- You can run a query in one project on data in another project. Make use of this where it makes sense.
Finally, remember the Principle of Least Privilege, don’t give users access to data they don’t need, and be particularly careful with PII data. You won’t get fined if your campaign performance report gets leaked, you will get fined if your customer table is published online!
Leave a Reply